Claude Mythos Preview: lanzamiento oficial con todos los benchmarks
Anthropic lanza Mythos Preview con acceso restringido. SWE-bench 93.9%, USAMO 97.6%, dominio total en los principales benchmarks.
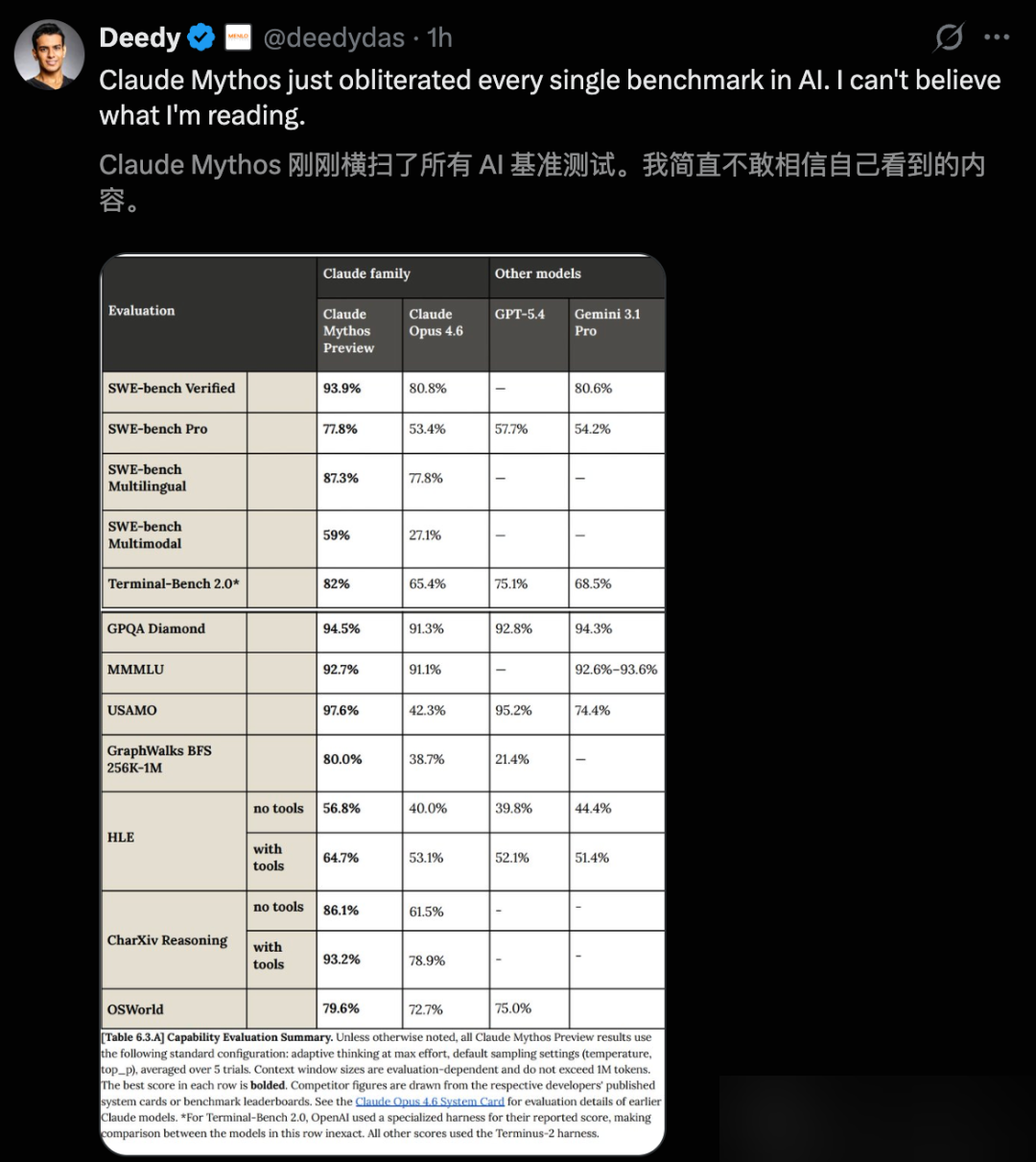
En resumen: Anthropic ha lanzado oficialmente Claude Mythos Preview. Cada cifra de benchmark confirma lo que la filtración de marzo insinuaba, y lo supera con creces. SWE-bench Verified: 93.9%. USAMO 2026: 97.6%. La brecha entre Mythos y Opus 4.6 no es incremental. Es generacional. El precio es 5 veces el de Opus 4.6. Acceso restringido a organizaciones aprobadas a través de Claude API, Amazon Bedrock, Vertex AI y Microsoft Foundry.
Los números son reales
Durante dos semanas, el mundo se basó en descripciones cualitativas de un borrador filtrado: “puntuaciones abrumadoramente superiores”, “muy por delante de cualquier otro modelo de IA”. Ahora tenemos los datos reales.
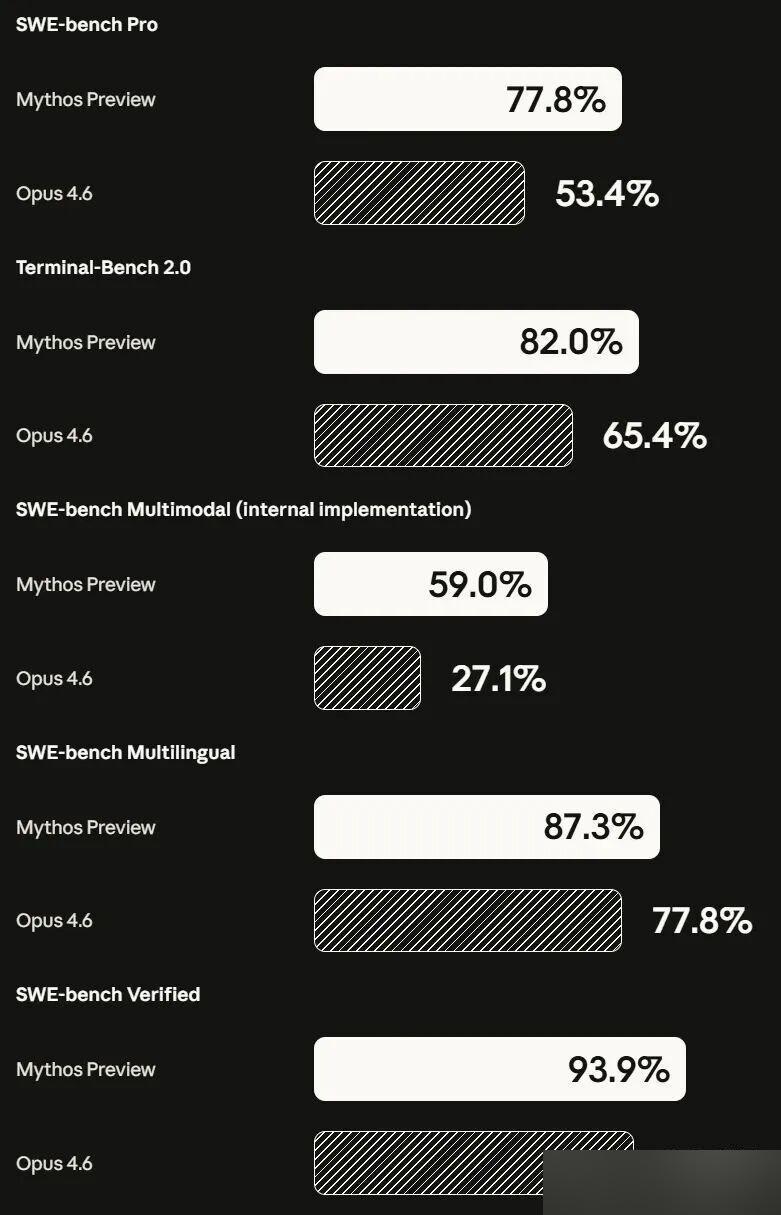
Comparación completa de benchmarks:
Programación
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 93.9% | 80.8% | — |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% |
| Terminal-Bench 2.0 | 82.0% | 65.4% | — |
| SWE-bench Multimodal | 59.0% | 27.1% | — |
SWE-bench Verified al 93.9%, una ventaja de 13.1 puntos sobre Opus 4.6. En SWE-bench Pro la brecha se amplía a 24.4 puntos. SWE-bench Multimodal es lo más dramático: Mythos más que duplica la puntuación de Opus 4.6.
Razonamiento y académico
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GPQA Diamond | 94.6% | — | — |
| HLE (con herramientas) | 64.7% | 53.1% | — |
| USAMO 2026 | 97.6% | 42.3% | — |
USAMO 2026 es la brecha más impactante del conjunto de datos. Opus 4.6 obtuvo 42.3%. Mythos Preview obtuvo 97.6%. Un examen de matemáticas de competición con 55.3 puntos de diferencia. En HLE — “El último examen de la humanidad” — Mythos sin herramientas externas superó a Opus 4.6 en 16.8%.
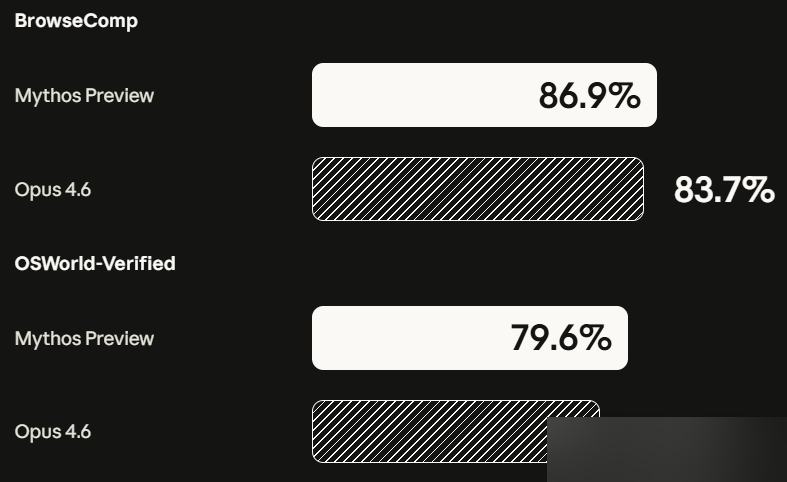
Tareas de agente
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| OSWorld (control de PC) | 79.6% | — | — |
| BrowseComp (búsqueda de info) | 86.9% | — | — |
Contexto largo
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GraphWalks (256K-1M tokens) | 80.0% | 38.7% | 21.4% |
GraphWalks evalúa razonamiento en contextos ultra-largos de 256K a 1 millón de tokens. Mythos Preview 80.0%, Opus 4.6 38.7%, GPT-5.4 solo 21.4%. Casi 4 veces mejor que GPT-5.4.
Ciberseguridad
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| CyberGym | 83.1% | 66.6% |
| Cybench (pass@1, 10 intentos) | 100% | — |
En los 35 desafíos CTF de Cybench, Mythos Preview resolvió todos con 10 intentos por desafío, pass@1 del 100%. CyberGym reproducción de vulnerabilidades: 83.1% vs 66.6% de Opus 4.6.
La valoración de Boris Cherny
Boris Cherny, creador de CC (Claude Code), fue conciso: “Mythos es muy poderoso y debería asustar.”
Anthropic venía usando Mythos internamente desde el 24 de febrero de 2026, más de cinco semanas antes del lanzamiento oficial. El período de despliegue interno les permitió validar las capacidades del modelo en flujos de trabajo de producción antes de abrir el acceso externo.
Precios y acceso
Mythos Preview tiene un precio de 5 veces el de Opus 4.6:
- Entrada: $25 por millón de tokens
- Salida: $125 por millón de tokens
Acceso a través de cuatro plataformas:
- Claude API (directo)
- Amazon Bedrock
- Google Vertex AI
- Microsoft Foundry
Mythos Preview no estará disponible para todos. El modelo de acceso restringido refleja tanto las capacidades del modelo como los riesgos documentados en la System Card de 244 páginas.
Por qué no hubo evento de lanzamiento
Estos números justificarían un gran lanzamiento de producto en cualquier otra empresa. Anthropic eligió un lanzamiento silencioso con acceso restringido.
La razón está documentada en la System Card y el blog del red team: las capacidades de ciberseguridad de Mythos Preview han cruzado un umbral visible. Descubrió miles de vulnerabilidades desconocidas en software de código abierto. Descubrió y explotó de forma independiente un zero-day de 27 años en OpenBSD. Logró 181 exploits funcionales en 250 intentos en el motor JavaScript de Firefox 147, mientras que Opus 4.6 solo consiguió 2.
El análisis completo de ciberseguridad y los hallazgos de la System Card se cubren en artículos separados.
Qué significa esto
La filtración de marzo usó palabras como “cambio cualitativo” y “puntuaciones abrumadoras”. Los números de abril demuestran que esas palabras se quedaron cortas. En cada dimensión — programación, razonamiento, matemáticas, tareas de agente, contexto largo, ciberseguridad — Mythos Preview no es marginalmente mejor que sus predecesores. Es categóricamente diferente.
La pregunta ya no es si Mythos es real. La pregunta es qué viene después.
Lecturas relacionadas
- Tres vulnerabilidades históricas — Cómo Mythos encontró bugs que sobrevivieron 27 años de revisión humana
- System Card de 244 páginas — Hallazgos sobre engaño, autoconciencia y Project Glasswing
- Comparación de modelos — Actualizado con datos oficiales
- Impacto en seguridad — Casos de estudio actualizados