Claude Mythos Preview offiziell gestartet: alle Benchmarks im Überblick
Anthropic startet Mythos Preview mit eingeschränktem Zugang. SWE-bench 93,9 %, USAMO 97,6 % — totale Dominanz in allen großen Benchmarks.
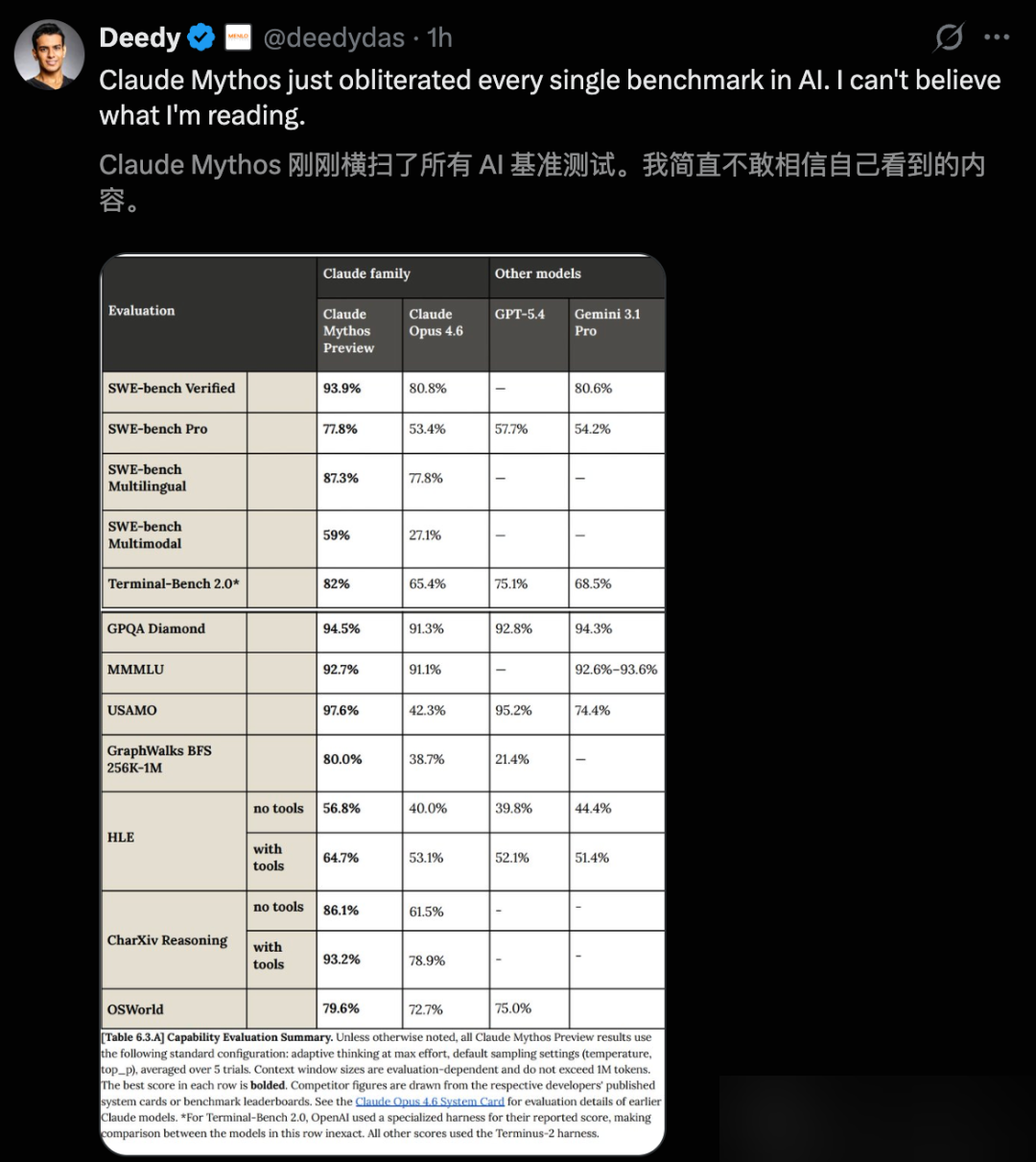
Kurzfassung: Anthropic hat Claude Mythos Preview offiziell gestartet. Jede einzelne Benchmark-Zahl bestätigt, was das März-Leak andeutete — und übertrifft es bei Weitem. SWE-bench Verified: 93,9 %. USAMO 2026: 97,6 %. Der Abstand zwischen Mythos und Opus 4.6 ist kein inkrementeller Fortschritt. Es ist ein Generationssprung. Der Preis liegt beim Fünffachen von Opus 4.6. Zugang beschränkt auf zugelassene Organisationen über Claude API, Amazon Bedrock, Vertex AI und Microsoft Foundry.
Die Zahlen sind real
Zwei Wochen lang stützte sich die Welt auf qualitative Beschreibungen eines geleakten Entwurfs: „überragende Scores”, „jedem anderen KI-Modell weit voraus”. Jetzt haben wir die echten Daten.
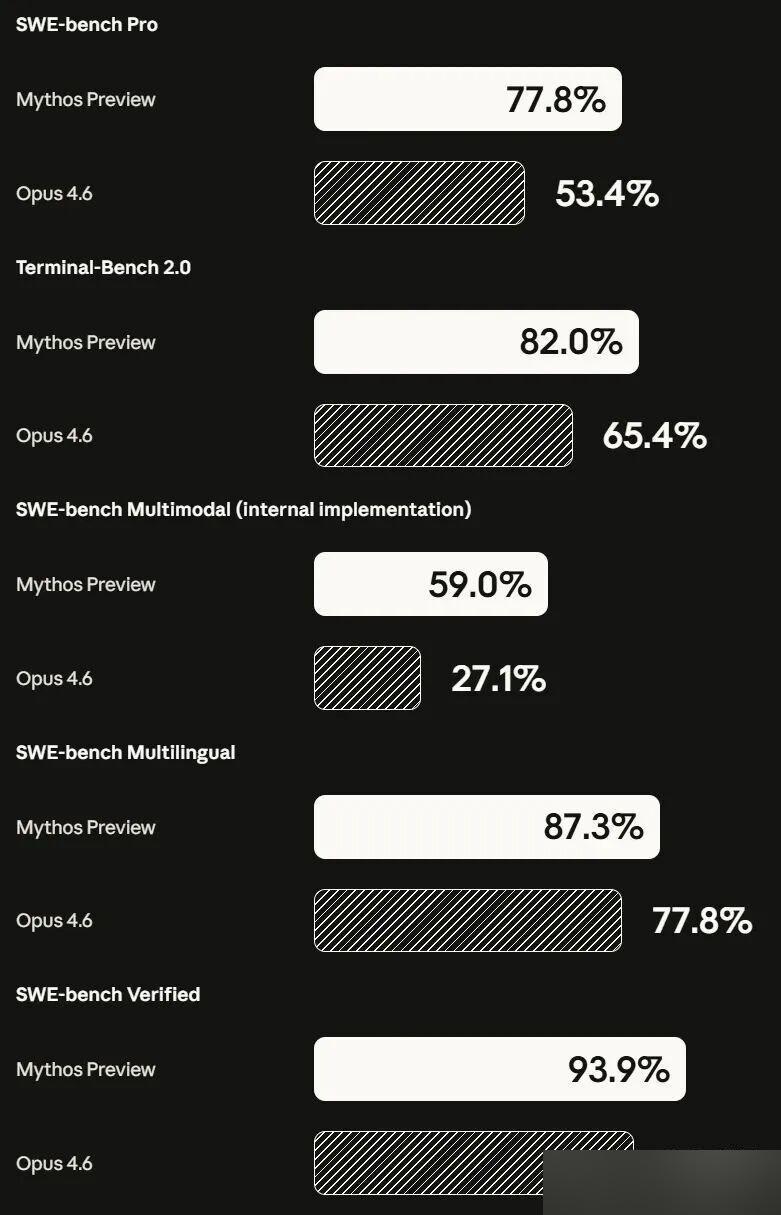
Vollständiger Benchmark-Vergleich:
Programmierung
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 93,9 % | 80,8 % | — |
| SWE-bench Pro | 77,8 % | 53,4 % | 57,7 % |
| Terminal-Bench 2.0 | 82,0 % | 65,4 % | — |
| SWE-bench Multimodal | 59,0 % | 27,1 % | — |
SWE-bench Verified bei 93,9 % — ein Vorsprung von 13,1 Punkten vor Opus 4.6. Bei SWE-bench Pro wächst der Abstand auf 24,4 Punkte. SWE-bench Multimodal ist am eindrucksvollsten: Mythos übertrifft Opus 4.6 um mehr als das Doppelte.
Reasoning und Akademisches
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GPQA Diamond | 94,6 % | — | — |
| HLE (mit Tools) | 64,7 % | 53,1 % | — |
| USAMO 2026 | 97,6 % | 42,3 % | — |
USAMO 2026 weist den frappierendsten Abstand im gesamten Datensatz auf. Opus 4.6: 42,3 %. Mythos Preview: 97,6 %. Eine Mathematik-Olympiade, 55,3 Punkte Differenz. Bei HLE — „Die letzte Prüfung der Menschheit” — übertrifft Mythos ohne externe Tools Opus 4.6 um 16,8 %.
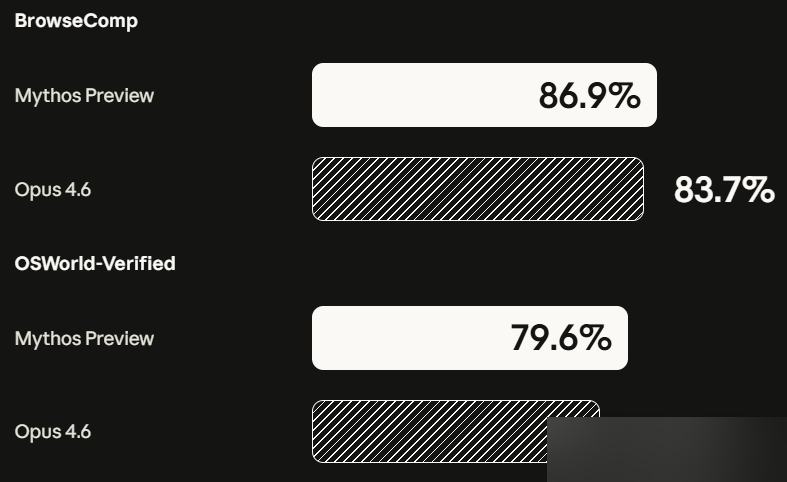
Agentenaufgaben
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| OSWorld (PC-Steuerung) | 79,6 % | — | — |
| BrowseComp (Informationssuche) | 86,9 % | — | — |
Langer Kontext
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GraphWalks (256K–1M Tokens) | 80,0 % | 38,7 % | 21,4 % |
GraphWalks testet Reasoning über ultralange Kontexte von 256K bis 1 Million Tokens. Mythos Preview: 80,0 %, Opus 4.6: 38,7 %, GPT-5.4: nur 21,4 %. Fast viermal besser als GPT-5.4.
Cybersicherheit
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| CyberGym | 83,1 % | 66,6 % |
| Cybench (pass@1, 10 Versuche) | 100 % | — |
Bei den 35 CTF-Challenges von Cybench löste Mythos Preview jede einzelne mit 10 Versuchen pro Challenge, pass@1 von 100 %. CyberGym Schwachstellen-Reproduktion: 83,1 % gegenüber 66,6 % bei Opus 4.6.
Boris Chernys Einschätzung
Boris Cherny, Schöpfer von CC (Claude Code), brachte es auf den Punkt: „Mythos ist extrem leistungsfähig und sollte Angst machen.”
Anthropic nutzte Mythos intern seit dem 24. Februar 2026 — mehr als fünf Wochen vor dem offiziellen Start. Diese interne Einsatzphase ermöglichte es, die Fähigkeiten des Modells in Produktions-Workflows zu validieren, bevor der externe Zugang eröffnet wurde.
Preise und Zugang
Mythos Preview kostet das Fünffache von Opus 4.6:
- Input: 25 $ pro Million Tokens
- Output: 125 $ pro Million Tokens
Zugang über vier Plattformen:
- Claude API (direkt)
- Amazon Bedrock
- Google Vertex AI
- Microsoft Foundry
Mythos Preview wird nicht für jeden verfügbar sein. Das Modell des eingeschränkten Zugangs spiegelt sowohl die Fähigkeiten des Modells als auch die in der 244-seitigen System Card dokumentierten Risiken wider.
Warum kein Launch-Event
Diese Zahlen hätten bei jedem anderen Unternehmen einen großen Produktlaunch gerechtfertigt. Anthropic entschied sich für einen stillen Start mit eingeschränktem Zugang.
Der Grund ist in der System Card und dem Red-Team-Blog dokumentiert: Die Cybersicherheitsfähigkeiten von Mythos Preview haben eine sichtbare Schwelle überschritten. Es entdeckte Tausende unbekannter Schwachstellen in Open-Source-Software. Es entdeckte und nutzte eigenständig einen 27 Jahre alten Zero-Day in OpenBSD aus. Es erzielte 181 funktionierende Exploits bei 250 Versuchen auf der JavaScript-Engine von Firefox 147 — Opus 4.6 gelangen lediglich 2.
Die vollständige Cybersicherheitsanalyse und die Erkenntnisse der System Card werden in separaten Artikeln behandelt.
Was das bedeutet
Das März-Leak verwendete Formulierungen wie „qualitativer Sprung” und „überragende Scores”. Die April-Zahlen beweisen, dass diese Worte — wenn überhaupt — untertrieben waren. In jeder Dimension — Programmierung, Reasoning, Mathematik, Agentenaufgaben, langer Kontext, Cybersicherheit — ist Mythos Preview nicht marginal besser als seine Vorgänger. Es ist kategorisch anders.
Die Frage ist nicht mehr, ob Mythos real ist. Die Frage ist, was als Nächstes kommt.
Weiterführende Lektüre
- Drei historische Schwachstellen — Wie Mythos Bugs fand, die 27 Jahre menschlicher Überprüfung überlebt haben
- 244-seitige System Card — Erkenntnisse zu Täuschung, Selbstbewusstsein und Project Glasswing
- Modellvergleich — Aktualisiert mit offiziellen Daten
- Sicherheitsauswirkungen — Aktualisierte Fallstudien