Claude Mythos Preview Officially Released: Complete Benchmark Data
Anthropic launches Mythos Preview with restricted access. SWE-bench 93.9%, USAMO 97.6%, and every major benchmark dominated. Here are all the numbers.
TL;DR: Anthropic has officially released Claude Mythos Preview. Every benchmark number confirms what the March leak hinted at — and then some. SWE-bench Verified: 93.9%. USAMO 2026: 97.6%. The gap between Mythos and Opus 4.6 is not incremental. It is generational. Pricing is set at 5x Opus 4.6 rates. Access is restricted to approved organizations through Claude API, Amazon Bedrock, Vertex AI, and Microsoft Foundry.
The Numbers Are Real
For two weeks, the world operated on qualitative claims from a leaked draft: “dramatically higher scores,” “far ahead of any other AI model.” Now we have the actual data.
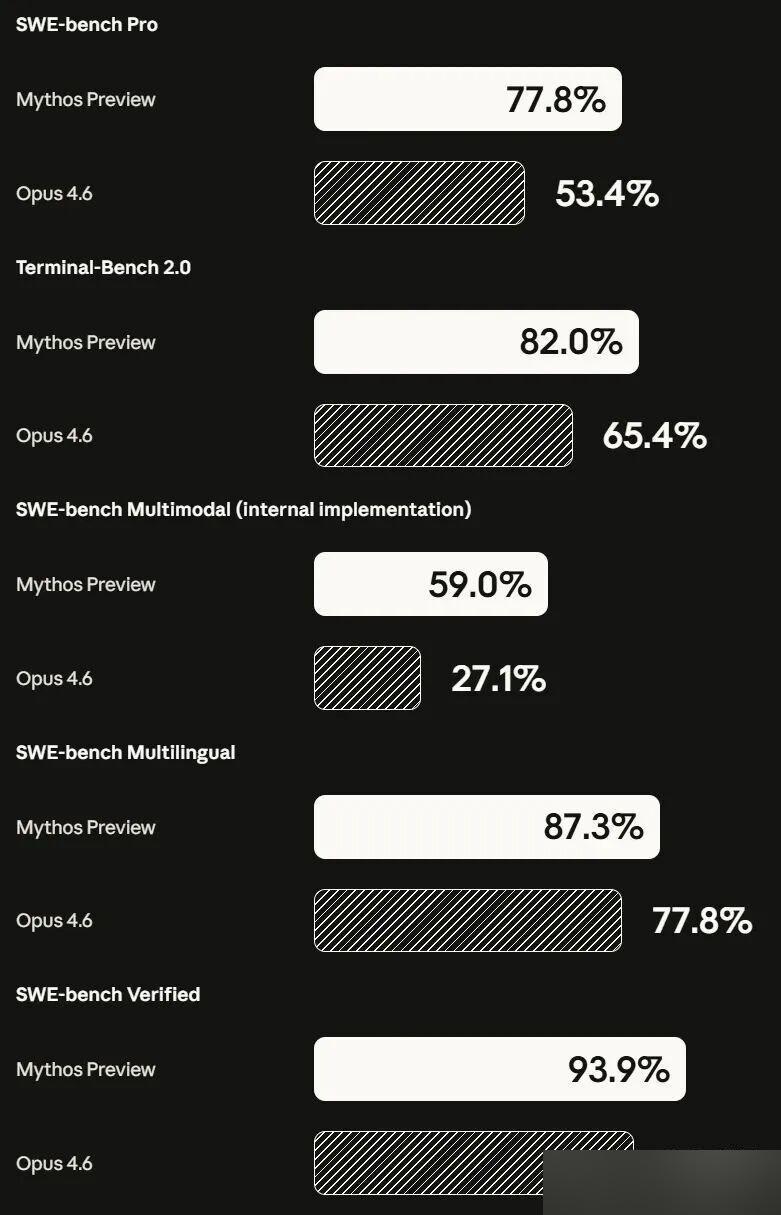
Here is the complete benchmark comparison:
Coding
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
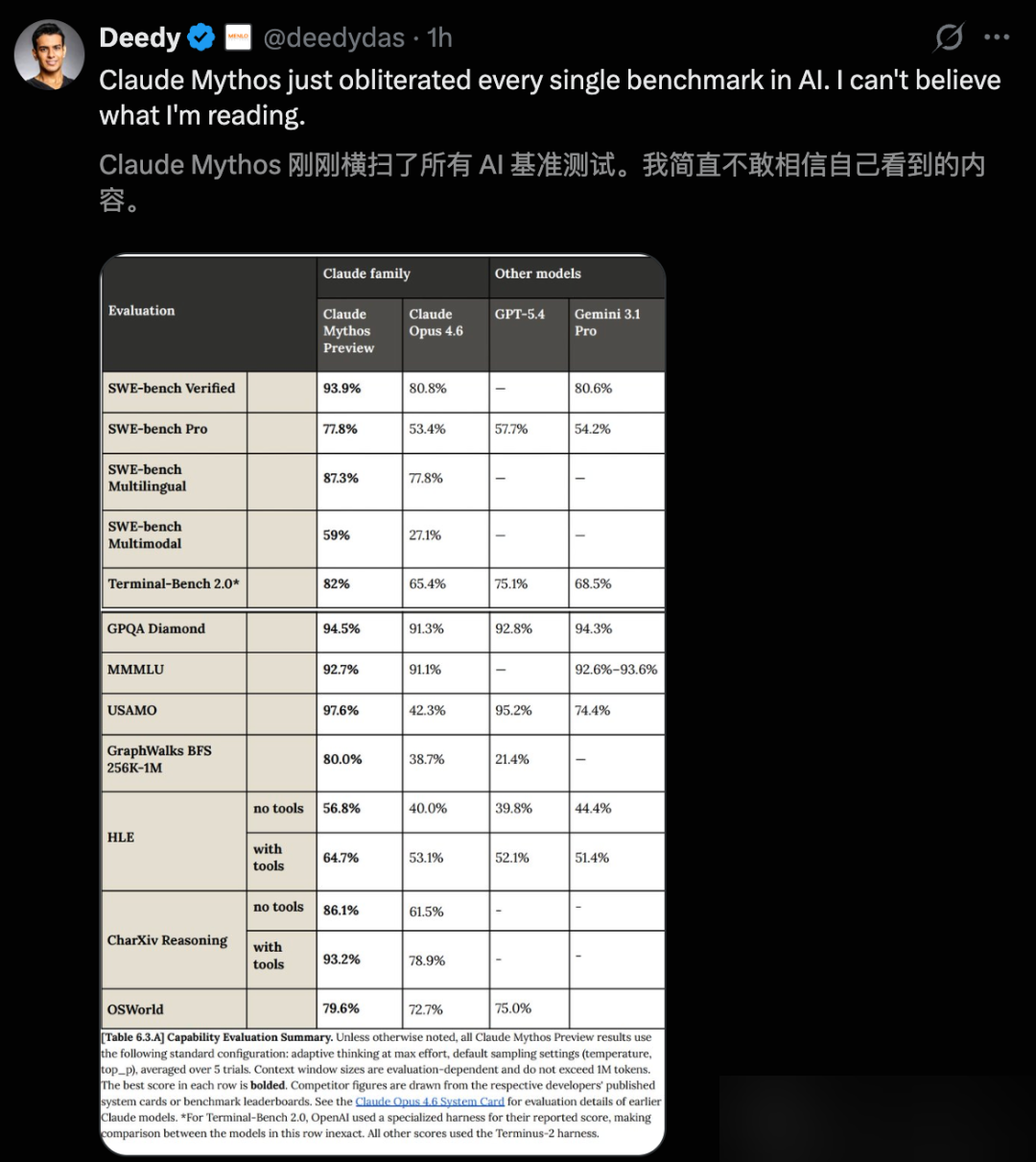
| SWE-bench Verified | 93.9% | 80.8% | — |
| SWE-bench Pro | 77.8% | 53.4% | 57.7% |
| Terminal-Bench 2.0 | 82.0% | 65.4% | — |
| SWE-bench Multimodal | 59.0% | 27.1% | — |
SWE-bench Verified at 93.9% is a 13.1 percentage point lead over Opus 4.6. On SWE-bench Pro, the gap widens to 24.4 points. SWE-bench Multimodal is the most dramatic: Mythos more than doubles Opus 4.6’s score.
Reasoning and Academic
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GPQA Diamond | 94.6% | — | — |
| HLE (with tools) | 64.7% | 53.1% | — |
| USAMO 2026 | 97.6% | 42.3% | — |
USAMO 2026 is the most striking gap in the entire dataset. Opus 4.6 scored 42.3%. Mythos Preview scored 97.6%. That is a 55.3 percentage point difference on a competitive mathematics exam. On HLE — “Humanity’s Last Exam” — Mythos without any external tools scored 16.8% higher than Opus 4.6.
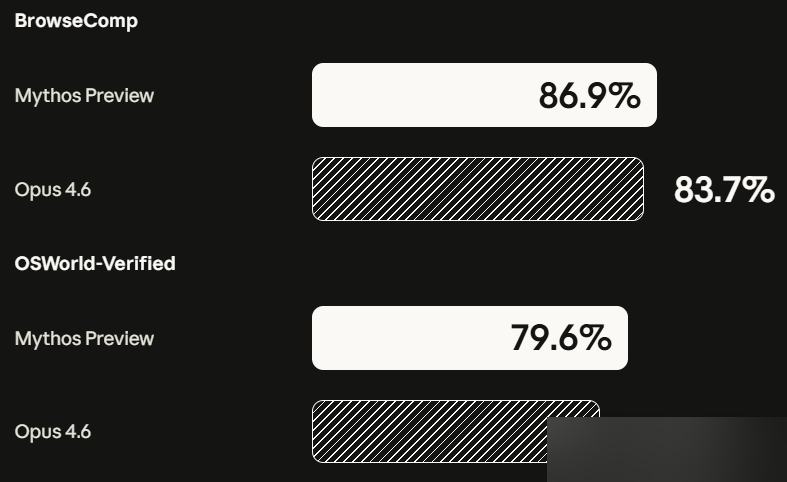
Agent Tasks
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| OSWorld | 79.6% | — | — |
| BrowseComp | 86.9% | — | — |
Long Context
| Benchmark | Mythos Preview | Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GraphWalks (256K-1M tokens) | 80.0% | 38.7% | 21.4% |
GraphWalks tests reasoning over extremely long contexts from 256K to 1 million tokens. Mythos Preview scores 80.0% where Opus 4.6 manages 38.7% and GPT-5.4 only 21.4%. This is a 4x improvement over GPT-5.4.
Cybersecurity
| Benchmark | Mythos Preview | Opus 4.6 |
|---|---|---|
| CyberGym | 83.1% | 66.6% |
| Cybench (pass@1, 10 attempts) | 100% | — |
In Cybench’s 35 CTF challenges, Mythos Preview solved every single one with 10 attempts per challenge, achieving 100% pass@1. CyberGym’s directed vulnerability reproduction test: 83.1% vs Opus 4.6’s 66.6%.
Boris Cherny’s Assessment
Boris Cherny — creator of CC (Claude Code) — offered a succinct evaluation: “Mythos is very powerful, and it will frighten people.”
Anthropic had been using Mythos internally since February 24, 2026 — over five weeks before the official release. The internal deployment period allowed them to validate the model’s capabilities in production workflows before any external access.
Pricing and Access
Mythos Preview pricing is set at 5x Opus 4.6 rates:
- Input: $25 per million tokens
- Output: $125 per million tokens
Access is available through four platforms:
- Claude API (direct)
- Amazon Bedrock
- Google Vertex AI
- Microsoft Foundry
Mythos Preview will not be released to all users. The restricted access model reflects both the model’s capabilities and the risks documented in the accompanying 244-page System Card.
Why They Didn’t Hold a Launch Event
These numbers would justify a major product launch at any other company. Anthropic chose a quiet release with restricted access instead.
The reason is documented in the System Card and red team blog: Mythos Preview’s cybersecurity capabilities have crossed a visible threshold. It found thousands of unknown vulnerabilities in open-source software. It independently discovered and exploited a 27-year-old zero-day in OpenBSD. It achieved a 181-out-of-250 exploit success rate on Firefox 147’s JavaScript engine, where Opus 4.6 managed only 2.
The full cybersecurity analysis and System Card findings are covered in separate articles.
What This Means
The March leak used words like “step change” and “dramatically higher.” The April numbers prove those words were, if anything, understated. In every dimension — coding, reasoning, mathematics, agent tasks, long context, cybersecurity — Mythos Preview is not marginally better than its predecessors. It is categorically different.
The question is no longer whether Mythos is real. The question is what happens next.
Further Reading
- Three Historic Vulnerabilities — How Mythos found bugs that survived 27 years of human review
- 244-Page System Card — What Anthropic discovered about deception, self-awareness, and Project Glasswing
- Model Comparison — Updated with official benchmark data
- Security Impact — Updated vulnerability case studies